Pada kesempatan kali ini saya akan membahas tentang AVL dan B-TREE .
AVL
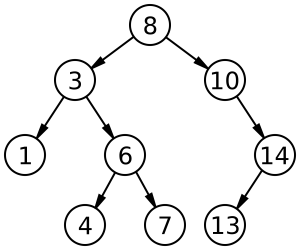
AVL merupakan kepanjangan dari Adelson Veleskii Landis Tree. AVL Tree adalah Binary Search Tree yang memiliki perbedaan tinggi/ level maksimal 1 antara subtree kiri dan subtree kanan.
AVL tree digunakan dalam binary search tree untuk menyeimbangkan dan menyederhanakan BST agar mudah untuk dicari, BST yang selisih Heightnya kurang dari -1 dan lebih dari 1 akan memerlukan Balancing.

Balancing memiliki beberapa kondisi, yaitu:
- Jika ada Unbalance pada anak kiri subtree kanan, maka dapat dilakukan rotasi kiri-kanan.
- Jika ada Unbalance pada anak kiri subtree kiri, maka dapat dilakukan rotasi kanan.
- Jika ada Unbalance pada anak kanan subtree kanan, maka dapat dilakukan rotasi kiri.
- Jika ada Unbalance pada anak kanan subtree kiri, maka dapat dilakukan rotasi kanan-kiri.
Insert AVL TREE
Ada 4 kasus yang biasanya terjadi saat operasi insert dilakukan, yaitu :
1 : node terdalam terletak pada subtree kiri dari anak kiri T (left-left)
2 : node terdalam terletak pada subtree kanan dari anak kanan T (right-right)
3 : node terdalam terletak pada subtree kanan dari anak kiri T (right-left)
4 : node terdalam terletak pada subtree kiri dari anak kanan T (left-right)
T adalah node yang harus diseimbangkan kembali.
4 kasus tersebut dapat diselesaikan dengan melakukan rotasi yaitu:
Kasus 1 dan 2 dengan single rotation
Kasus 1 dan 2 dengan single rotation
Kasus 3 dan 4 dengan double rotation.
Delete AVL TREE
Delete AVL TREE
Deletion dalam AVL Tree sama seperti teknik deletion dalam binary search tree yang tidak seimbang.
Ada 2 kasus yang biasanya terjadi saat operasi delete dilakukan yaitu
Jika node yang akan dihapus berada pada posisi leaf atau node tanpa anak, maka dapat langsung di hapus.
Jika node yang akan dihapus memiliki anak, maka proses penghapusannya harus di cek kembali untuk menyeimbangkan Binary Search Tree dengan perbedaan tinggi / level maksimal 1.
Jika node yang akan dihapus berada pada posisi leaf atau node tanpa anak, maka dapat langsung di hapus.
Jika node yang akan dihapus memiliki anak, maka proses penghapusannya harus di cek kembali untuk menyeimbangkan Binary Search Tree dengan perbedaan tinggi / level maksimal 1.
Anggap T adalah node yang harus diseimbangkan kembali
1 : node terdalam terletak pada subtree kiri dari anak kiri T (left-left)
2 : node terdalam terletak pada subtree kanan dari anak kanan T (right-right)
3 : node terdalam terletak pada subtree kanan dari anak kiri T (right-left)
4 : node terdalam terletak pada subtree kiri dari anak kanan T (left-right)
B-TREE
B-Tree adalah pohon seimbang yang dioptimalkan untuk situasi saat sebagian atau seluruh pohon harus dipertahankan dalam penyimpanan sekunder seperti disk magnetik . Karena akses disk yang mahal ( memakan waktu ) operasi , b-tree mencoba untuk meminimalkan jumlah akses disk . Sebagai contoh, b - tree dengan ketinggian 2 dan faktor percabangan 1001 dapat menyimpan lebih dari satu miliar kunci tetapi membutuhkan paling banyak dua akses disk untuk mencari setiap node.
Karakteristik B-Tree:
- Semua daun akan dibuat pada level yang sama.
- B-Tree ditentukan oleh sejumlah derajat, yang juga disebut "urutan" (ditentukan oleh aktor eksternal, seperti programmer), disebut sebagai m
- Subtree kiri dari node akan memiliki nilai lebih rendah dari sisi kanan subtree. Ini berarti bahwa node juga diurutkan dalam urutan menaik dari kiri ke kanan.
- Jumlah maksimum node anak, sebuah simpul root serta simpul turunannya dapat dihitung dengan rumus ini: m-1
Keuntungan menggunakan B-Tree:
- Mengurangi jumlah pembacaan yang dilakukan pada disk
- Pilihan yang baik untuk memilih ketika proses reading dan writing pada blok data yang besar
- B Tree dapat dengan mudah dioptimalkan untuk menyesuaikan ukurannya (yaitu jumlah node anak) sesuai dengan ukuran disk
- Ini adalah teknik yang dirancang khusus untuk menangani sejumlah besar data.
- Algoritma yang paling tepat untuk database dan sistem file.
Insert
Syarat insertion yaitu:
· Pertama tentukan dahulu dimana key akan diletakkan menggunakan algoritma search, key pasti ditempatkan pada node leaf.
· Jika node tadi adalah 2-node, maka letakkan saja key tersebut disitu.
· Jika nodenya adalah 3-node, maka jadikan data tengah dari key, A, dan B
Delete
Syarat Deletion yaitu:
· Tentukan di node mana data yang ingin dihapus,
· Jika berada dalam 3-node, langsung hapus saja datanya.
· Jika berada dalam 2-node :
Jika parent adalah 3-node : ambil satu data dari parent.Jika sibling adalah 3-node, ambil salah satu data nya untuk dijadikan data pada parent (agar parent menjadi 3-node lagi).Jika sibling adalah 2-node, buat parent menjadi 2-node dengan menggabungkan (merge) sibling dengan node tempat data didelete.- Jika parent adalah 2-node : Jika sibling adalah 3-node, turunkan data parent ke node dan ambil satu data dari sibling untuk menggantikan parent. Jika sibling 2-node, gabungkan sibling dengan node yang dihapus datanya.